Thesis Statement
"Through my dissertation, I introduce a causally grounded, extensible, approach for rating AI models for robustness by detecting their sensitivity to input perturbations and protected attributes, quantifying this behavior, and translating it into user-understandable ordinal ratings (trust certificates). "
Abstract
This dissertation examines how to assess and rate instability and bias in black-box AI models, with particular attention to large language models (LLMs) and composite AI models used in finance, healthcare, and other decision-sensitive contexts. Prior studies show that small changes in input or protected attributes (sensitive user information) can cause large shifts in model outputs, an issue that becomes more pronounced when multiple models are chained together to form a composite AI model.
The work introduces a causality-based rating method that tests black-box models to quantify sensitivity, statistical bias, and confounding effects under controlled input variations. Beyond measurement, the rating method converts raw metric scores into comparable ratings that aid users in model selection, provide holistic explanations when used in conjunction with traditional explanation methods to cater to the needs of multiple stakeholders, and support the assessment and construction of robust and efficient composite AI models when integrated with probabilistic planning methods. The rating method helps users make trade-offs among fairness, utility, and computational cost when choosing a model for a task based on the data in hand.
To support practical adoption, the dissertation presents ARC (AI Rating through Causality), a tool that applies the method across multiple tasks, supports Pareto analysis, and allows users to evaluate their own models within a fixed causal setup. User studies show that ratings reduce the effort required to understand model behavior and help users build efficient composite chatbots. This work also underpins a forthcoming Springer Nature book, Assessing, Explaining, and Rating AI Systems for Trust, With Applications in Finance.
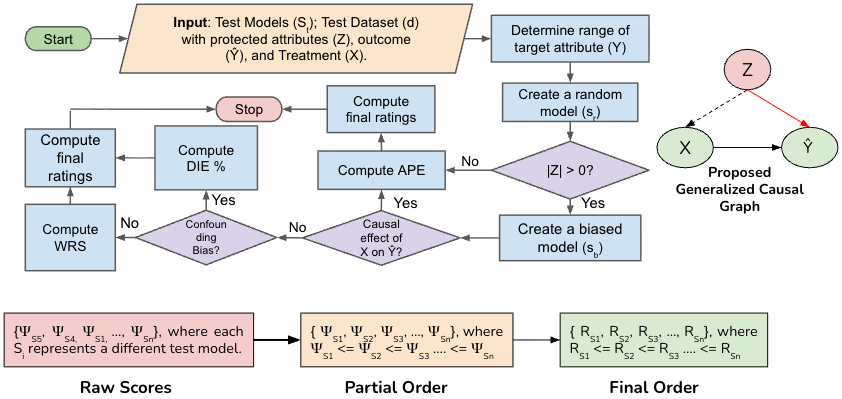
Rating Workflow
From Predictions to Ratings











